Best practice สำหรับการทำ service maintanance host server ที่อยู่ใน cluster ก่อนที่จะ reboot server นั้น ควรมีขั้นตอนการทำงานเพื่อป้องกันความผิดพลาดหรือความเสียหายที่อาจเกิดขึ้นกับระบบได้ เป็นการจัดการความเสี่ยงอย่างหนึ่งที่สำคัญมาก โดยมีหลักการ คือ หากต้องการ service maintanance host server ใด ให้ทำการ clear ให้ว่างก่อน โดยมีส่วนที่จะให้ความสำคัญ คือ
- Roles(vm) ที่เป็น member owner node ของ server นั้นให้ย้ายออกไปที่ node อื่น
- Disks volume ในกรณีที่ Cluster นั้นมีทำงานระบบ Storage Space Direct (S2D) ให้ย้าย owner nodes ไปที่ node อื่นด้วย
- Node ให้ทำ drain roles เพื่อหยุดสถานะการทำงานใน cluster ไว้ก่อน (pause)
การทำ drain roles นั้นสามารถป้องกันปัญหาที่อาจจะเกิดขึ้นหลังจากการทำ service maintance เช่น หาก reboot server แล้วมีข้อผิดพลาด vm จะไม่ทำการ migration กลับมาอัตโนมัติ หรือหากต้อง reboot node มากกว่า 1 ครั้ง อาจทำให้เกิดความเสียหายระหว่างการทำ migration หรือ หาก cluster นั้นมีระบบ storage space direct ด้วย หลังจากการ reboot node ใน member ระบบจะทำการ regeneration storage jobs หากอยู่ในการทำงานนี้แล้ว node มีการ reboot อีก อาจทำให้เกิดความเสียหายกับ storage volume ได้
ในส่วนนี้จะพูดถึงการทำ drain roles โดยมีวิธีการทำดังนี้
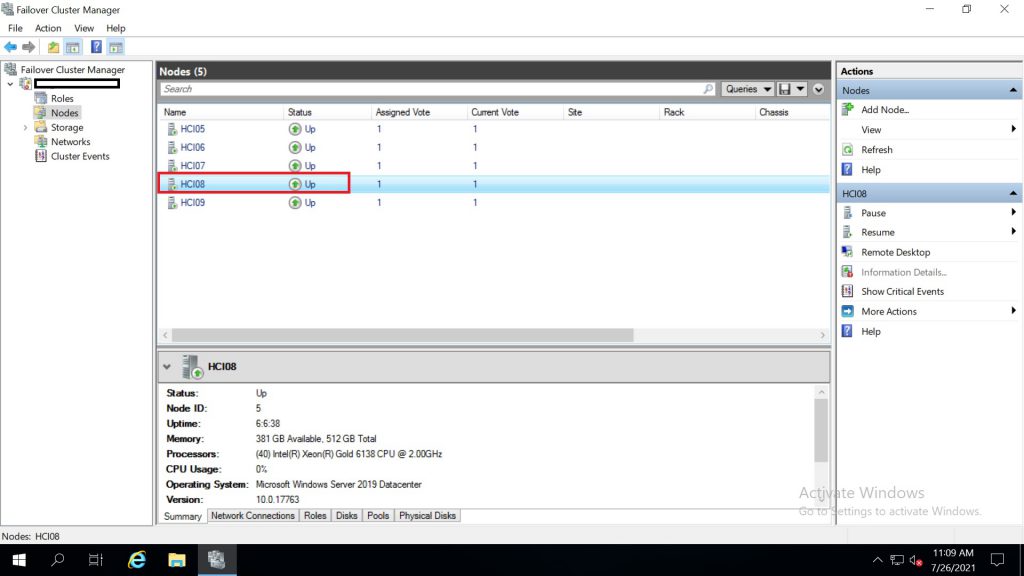
ให้เข้าสู้ failover cluster manager ไป Nodes
เลือก node ที่ต้องการ ไปด้านขวาเลือก pause
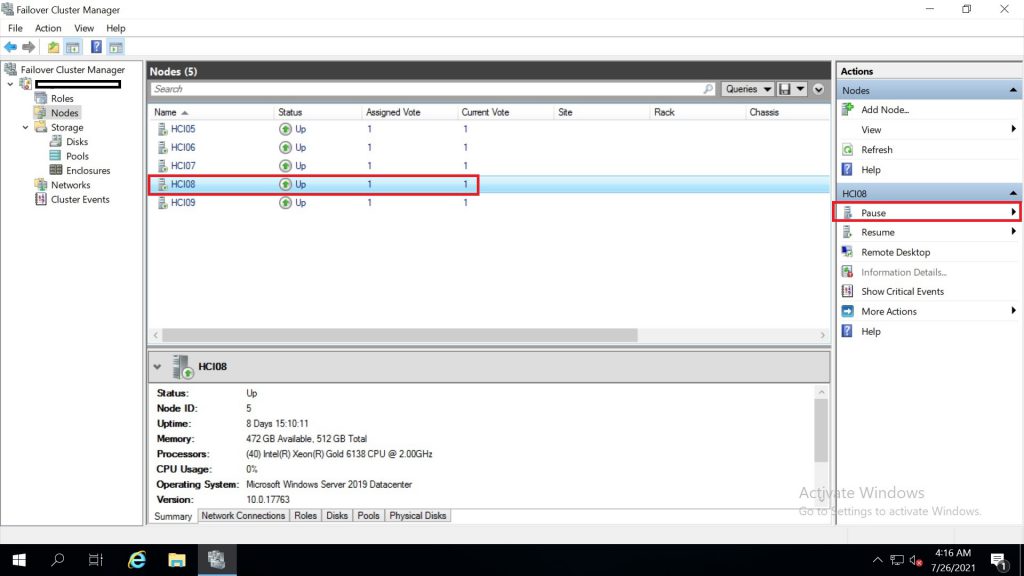
หัวข้อ pause เมื่อกดที่ list ให้เลือกที่ Drain Roles
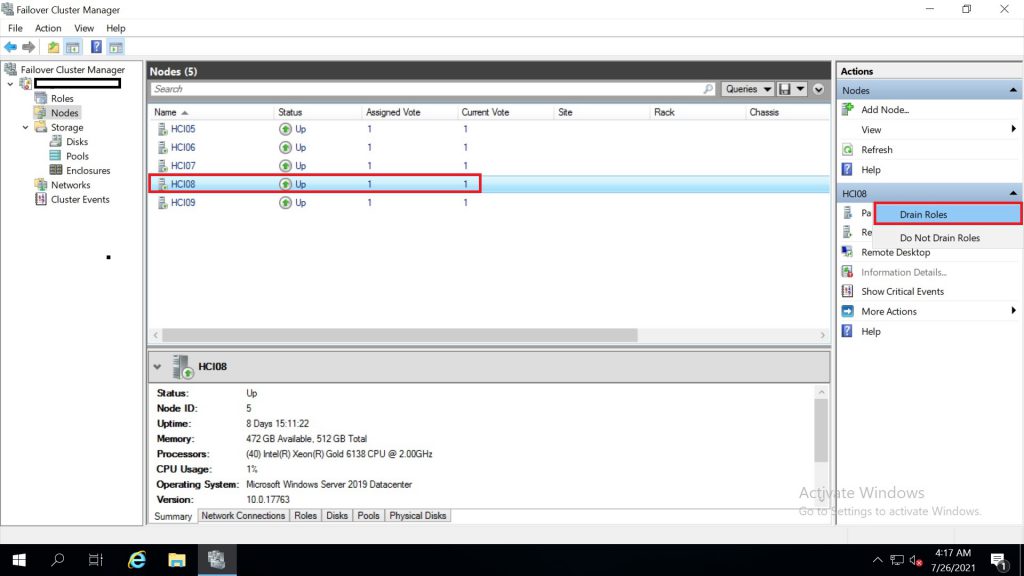
ระบบกำลังทำ draining node : ในขั้นตอนนี้ ระบบจะทำการ migration vm และ disks owner ไปที่ node อื่น
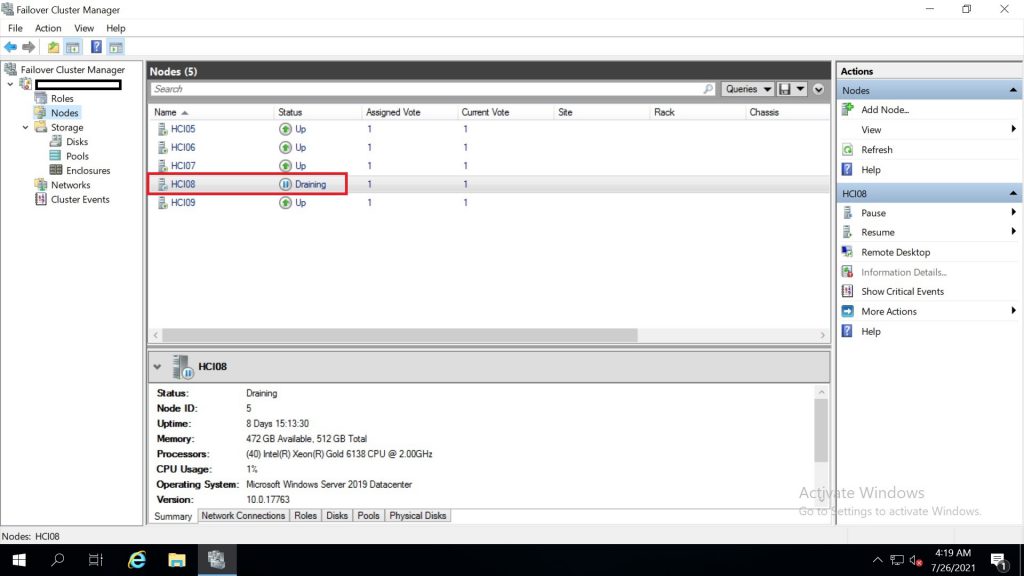
เมื่อทำการ drain roles เสร็จแล้วจะเปลี่ยนสถานะจาก draining เป็น paused พร้อมสำหรับการทำ service maintanance , windows updates หรือ reboot แล้ว
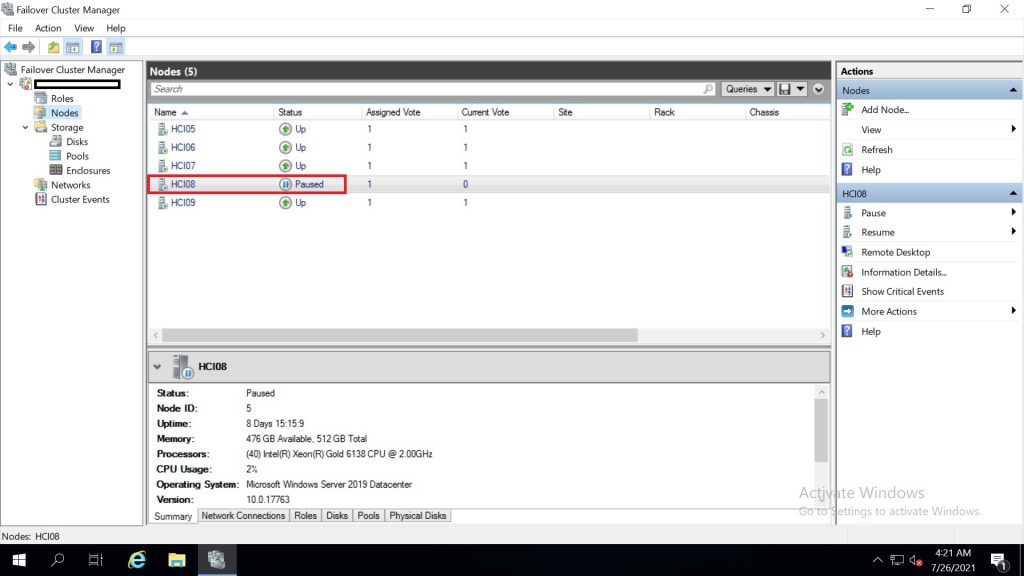
เมื่อ reboot node สถานะจะเปลี่ยนไปเป็น down
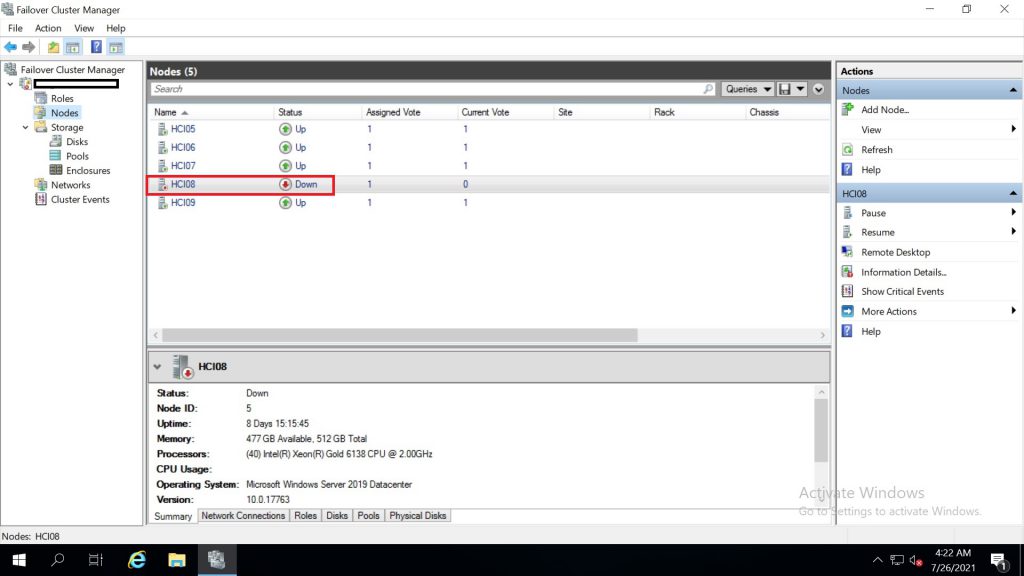
เมื่อ node reboot เสร็จแล้วจะกลับสูสถานะ paused ดังเดิม ในกรณีที่ต้องทำ service maintanance หรือ reboot อีกให้ทำให้เสร็จในขั้นตอนนี้
เมื่อทำ maintanance เสร็จแล้ว จะนำ node เข้าสู่สถานะปรกติของ cluster ให้ไปที่หัวข้อ resume
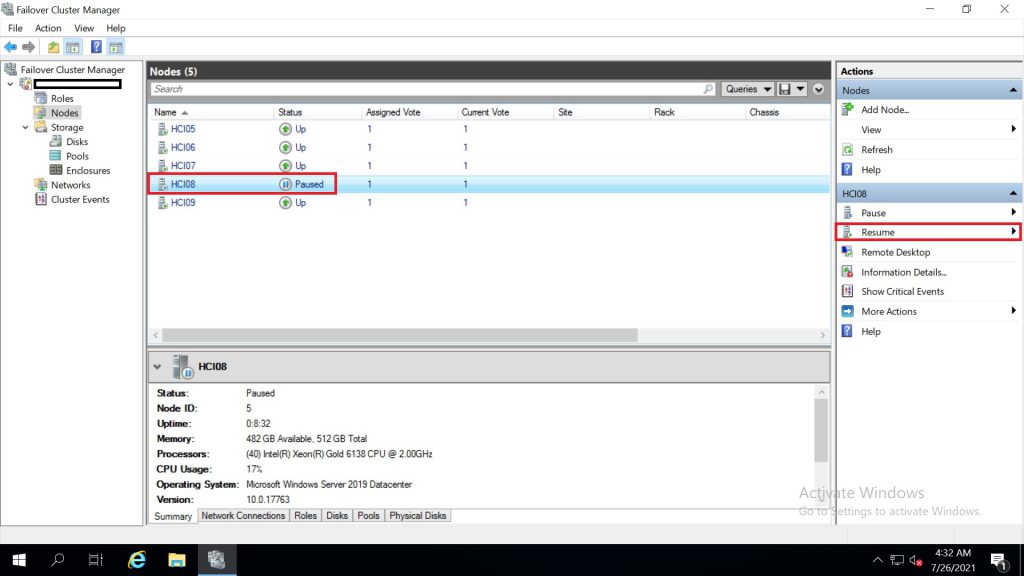
จะมีหัวข้อ 2 หัวข้อ
Fail roles back คือ สถานะของ roles และ disks owner จะอยู่ในสถานะก่อนการทำ drain roles
Do not fail roles back คือ สถานะของ roles และ disks owner จะอยู่สถานะหลังจาก drain roles
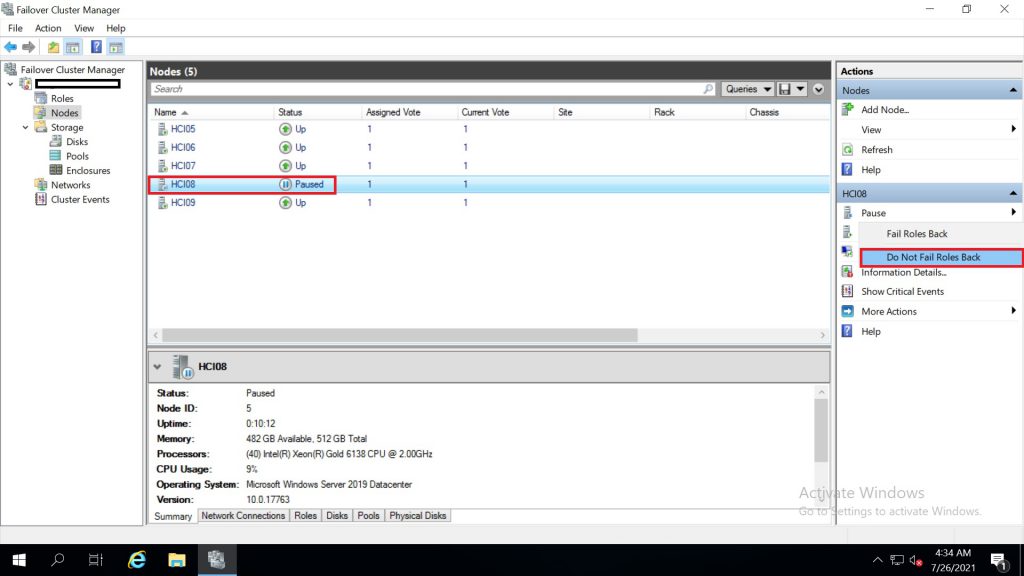
กลับเข้าสู่ cluster ตามปรกติ